


The Layman’s Introduction to DeepSeek-R1 Training
Deepseek surpassed ChatGPT to become...

Yesterday, NVIDIA lost more than $600 billion in value because of fears that DeepSeek’s ability to train powerful LLMs at low cost means we might not need as many GPUs as previously thought to build AGI. After all, DeepSeek does not have access to as many high-end GPUs as OpenAI, yet it was able to create a model on par with OpenAI’s o1 at a fraction of its cost. It’s an impressive feat.
Deepseek surpassed ChatGPT to become the top app on the App Store in the US. I think it is fair to say DeepSeek is having its ChatGPT moment.

I won’t go into detail about whether or not the NVIDIA (or AI-tech-related stock selloff) is warranted. Obviously, I am not giving financial advice in this newsletter. Over the weekend, a lot of people argued that the selloff is based on a wrong understanding of what is going to happen next. A lot of people (Microsoft’s CEO Satya Nadella included) have invoked Jevons Paradox, which is simply the idea that as a commodity becomes cheaper or more efficient to use, overall consumption of that commodity tends to increase rather than decrease. This counterintuitive effect occurs because improvements in efficiency lower the cost of using the resource, making it more attractive for consumption, which can ultimately lead to greater total demand rather than conservation.
People are assuming that DeepSeek’s efficiency means fewer GPUs will be needed overall. In essence, Jevons Paradox suggests that instead, cheaper AI training will lead to an explosion in demand for AI models and, in turn, more GPUs to train and serve those models. Moreover, the race to AGI will likely increase computational needs, not reduce them. NVIDIA’s stock rallied today, so I guess many investors believe that the Jevons Paradox applies to high-end GPUs.
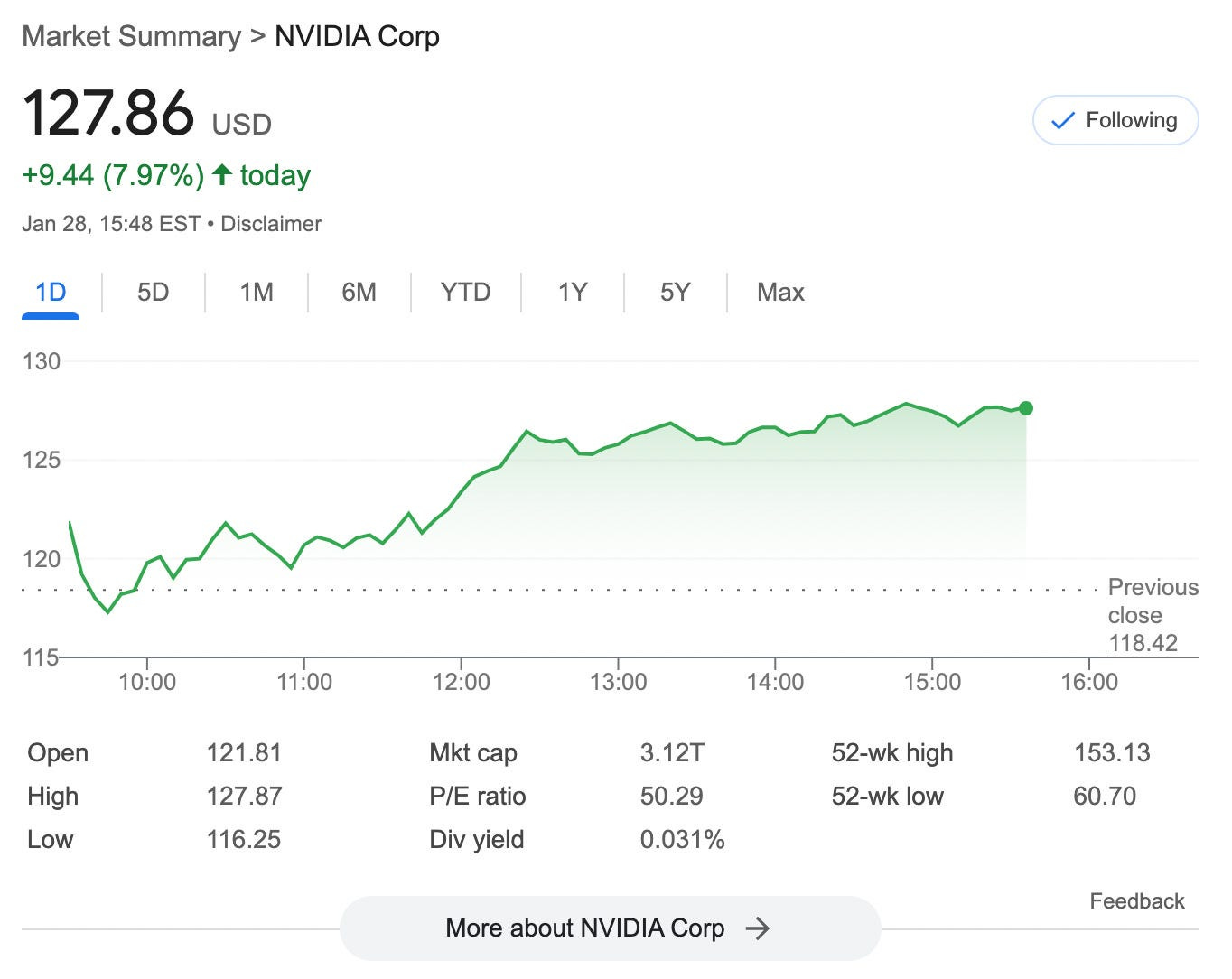
But is there a scenario where yesterday’s selloff, while mostly fear-driven, ends up being right? I did a bit of research, and the short answer is yes. There are a lot of powerful open-source models, and companies might mostly do fine-tuning,which is less GPU-intensive. If fewer companies need to train large models from scratch, that reduces demand for expensive GPU clusters. NVIDIA benefits mostly from high-end AI training workloads, but if most AI workloads shift to fine-tuning and inference, it weakens NVIDIA’s long-term advantage.
That’s it for the stock market commentary. This post is going to be a bit technical going forward. I will mostly try to explain as simply as possible the training recipe of DeepSeek-R1. I spent a bunch of hours reading the DeepSeek paper — I learned a lot along the way.
Training DeepSeek-R1
DeepSeek-R1 is a reasoning model that was trained mainly using reinforcement learning (RL). It’s called a reasoning model, but at its core, it is still a large language model that just goes through specific post-training. The purpose of post-training phase, at least in this case, is to make the model better at reasoning-intensive tasks like solving math problems, coding problems, or general problems that require logical reasoning.
To understand how DeepSeek-R1 was trained and why, one has to understand how DeepSeek-R1-Zero was trained. DeepSeek-R1-Zero was basically an experiment to see if pure RL could be efficient in helping LLMs acquire better reasoning ability. The positive results obtained informed the design of the pipeline that was used to train DeepSeek-R1.
Training DeepSeek-R1-Zero
Like I said, DeepSeek-R1-Zero was trained purely through reinforcement learning without supervised fine-tuning (contrary to traditional models). This is a pretty different approach from what was common practice until now.
The traditional method of training large language models (LLMs) goes like this:
The model is first pre-trained on large-scale text corpora (e.g., books, web pages) in an unsupervised manner. Here, the objective of the training is just for the model to be good at predicting the next token.
It is then fine-tuned using labeled datasets with human-verified responses to improve its performance on specific tasks such as:
Reasoning (solving math problems with step-by-step solutions)
Coding (writing correct programs)
Question Answering (fact-based or multi-step responses)
Dialogue (improving natural conversation flow)
The fine-tuning process guides the model by explicitly providing correct answers, making it more structured and reliable. For a reasoning task, the dataset may contain question-answer pairs with step-by-step reasoning or Chain of Thoughttraces (CoT). Here is an example:
Question: What is the result of 2 + 2 × (1 + 3)?
Answer: I first need to compute 1 + 3, which equals 4. Since multiplication has higher priority than addition, I have to compute 2 × 4 next, which yields 8, and finally, I add 2 + 8. So the final result is 10.
This is the supervised fine-tuning (SFT) I mentioned previously — supervised because there has to be a human-labeled dataset of questions and answers (including CoT) to teach reasoning to the model. DeepSeek-R1-Zero didn’t go through this part. Instead, DeepSeek-R1-Zero begins with DeepSeek-V3-Base, a pre-trained model with general knowledge. It is then directly trained using RL.
How does it work in practice? The model generates multiple possible answers to a reasoning problem using sampling (the famous temperature parameters). A rule-based reward model evaluates these answers based on accuracy and format (having these tags: <think> </think>, with the reasoning inside). If the reasoning path is correct, it gets a positive reward; if incorrect, it gets a penalty. Over thousands of iterations, the model learns to refine its reasoning steps independently.
To reduce the training costs of RL, DeepSeek’s team decided to forgo the classic Proximal Policy Optimization (PPO)algorithm in favor of a custom algorithm of their creation: GRPO (Group Relative Policy Optimization). I won’t go into the details of this here — RL is a relatively complex and wonkish domain. But suffice it to say the RL algorithm is a way to do soft backpropagation based on the feedback of a reward. For example, you want to reward the model for good CoT reasoning that leads to a correct answer and ‘punish’ it for false answers. So at the end of the day, it is still backpropagation, and the process is typically as follows:
Generate responses → Score them → Compute policy ratios → Clip updates (so they are soft) → Backpropagate → Repeat
The result of the DeepSeek-R1-Zero experiment was immediately promising. With pure RL, the model was able to reach SOTA performance on reasoning-heavy benchmarks like AIME 2024, MATH-500, or CodeForces. I think the eureka moment of the DeepSeek team was probably when they saw these results.
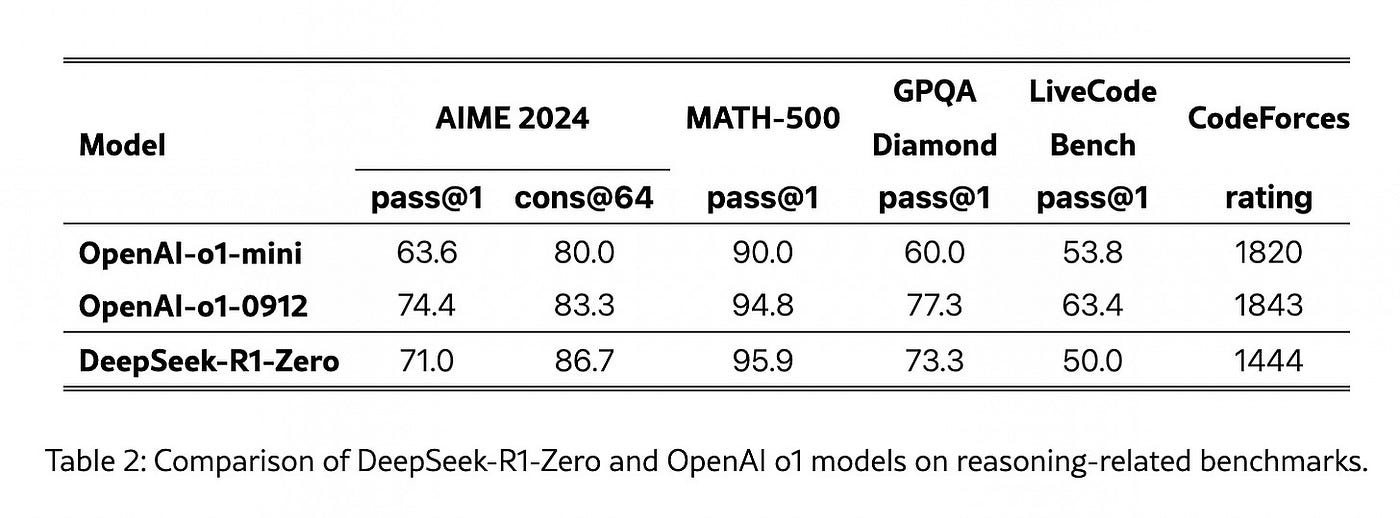
But not everything was perfect. DeepSeek-R1-Zero’s outputs were often poorly readable, and its reasoning traces frequently exhibited language mixing (CoT containing english and chinese for example). To mitigate that issue and create a better model, DeepSeek’s team came up with a new recipe.
The DeepSeek-R1 Recipe
The transition from DeepSeek-V3 base to DeepSeek-R1 involved a multi-stage training process to address the issues of poor readability and language mixing in DeepSeek-R1-Zero while further enhancing reasoning performance. Here’s how the process went:
Cold Start Finetuning
First, a small amount of long CoT data (10k) was collected from finetuned models, R1-Zero, and human annotators. That dataset was then used to finetune the DeepSeek-V3 base model. The goal here was to increase readability and coherence.
Reasoning-Oriented RL
The model obtained from the previous finetuning step went through RL, exactly like R1-Zero. A rule-based reward model — based on accuracy, format, and language consistency (added to prevent the language mixing observed in R1-Zero). The same dataset of reasoning QA pairs used for R1-Zero (math, coding, science, and logical reasoning) was used here as well.
Finetuning for Reasoning and General NLP Tasks
Here’s where it gets interesting. I initially expected this finetuning to be applied to the model obtained after the previous RL step. I had to double-check this, but DeepSeek actually applies it to the DeepSeek-V3 base. The model obtained from the previous RL step is only used to generate a synthetic reasoning dataset of 600K samples. DeepSeek’s team performed rejection sampling, used DeepSeek-V3 as a judge, and filtered the results to remove mixed languages, long paragraphs, and code blocks.
They then combined the synthetic reasoning dataset with a non-reasoning one (200K) containing other common NLP tasks (role-playing, translation, etc.). I think the purpose of adding the non-reasoning samples is to achieve a “balanced” finetuning, preventing the model from skewing too much toward reasoning approaches for standard NLP tasks that may be straightforward.
RL for Human Preferences and Reasoning
Finally, the finetuned version of DeepSeek-V3 base obtained from the previous step goes through a final RL stage based on a combination of reward signals: rule-based rewards for reasoning (like in DeepSeek-R1-Zero) and a neural reward model for human preferences.

DeepSeek-R1 is thus a feat of clever engineering — a carefully crafted model that benefits from both supervised finetuning and reinforcement learning.
My intuition about RL is that it increases the probability of the model remembering certain textual reasoning approaches and general facts. Fundamentally, I see it as memorization masquerading as reasoning, as it involves memorization of parameterized patterns. As such, I suspect there is an upper limit to the performance gains achievable through RL.
What I mean by that is: you can’t expect that throwing ever more compute at RL will lead to better reasoning in a general sense. However, curating large synthetic reasoning datasets from RL and using them for finetuning might improve the performance of LLMs on reasoning benchmarks in the short to medium term. In other words, o4, R3, and R4 will likely exhibit increasingly better reasoning performance on benchmarks (especially for closed problems) but less so on general problems.
That said, I see huge opportunities in applying the DeepSeek-R1 recipe to solve a variety of economically useful problems. I’ll probably write more about this later.
For now, go enjoy the whale!
Hello there,
I hope this communique finds you in a moment of stillness. Have huge respect for your work.
We’ve just opened the first door of something we’ve been quietly crafting for years—
A work not meant for markets, but for reflection and memory.
Not designed to perform, but to endure.
It’s called The Silent Treasury.
A place where judgment is kept like firewood: dry, sacred, and meant for long winters.
Where trust, patience, and self-stewardship are treated as capital—more rare, perhaps, than liquidity itself.
This first piece speaks to a quiet truth we’ve long sat with:
Why many modern PE, VC, Hedge, Alt funds, SPAC, and rollups fracture before they truly root.
And what it means to build something meant to be left, not merely exited.
It’s not short. Or viral. But it’s built to last.
And if it speaks to something you’ve always known but rarely seen expressed,
then perhaps this work belongs in your world.
The publication link is enclosed, should you wish to open it.
https://helloin.substack.com/p/built-to-be-left?r=5i8pez
Warmly,
The Silent Treasury
A vault where wisdom echoes in stillness, and eternity breathes.